Pandas and the UPRN
Published on July 28, 2017
The UPRN (Unique Property Reference Number) is a nice idea. Essentially a barcode for the lifecycle of a property this piece of data can be used to uniquely identify any valid property. It is the crux of the address gazetteers in the UK, used in AddressBase and provides the de-facto option which which other datasets can be joined to properties.
In practise the UPRN is numeric datatype that is 12 digits in length (AddressBase technical specification)
While on the face of it this is straight-forward a UPRN record is long enough to be interpreted in a number of ways as a 12 digit number can be long enough to be interpreted under scientific notation in Excel.
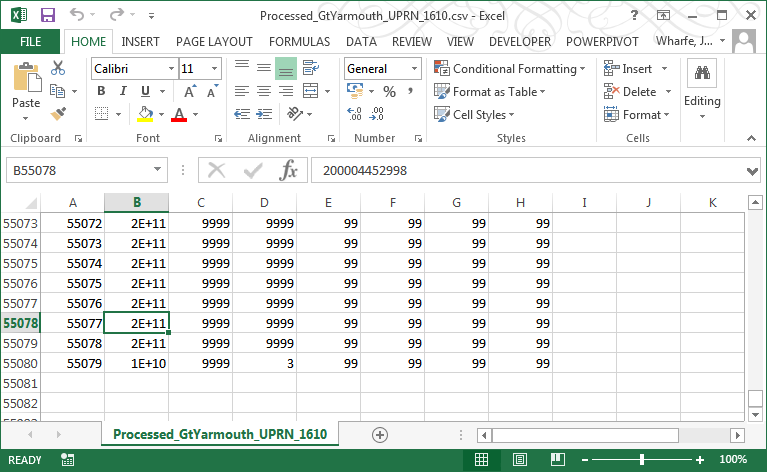
The same thing occurs where loading the data into a Pandas dataframe. If fact, so far where loading a source dataset containing UPRN values into Pandas, the UPRN has been interpreted as four datatypes - int; long; float; and string
This is a concern as the enormous power of the UPRN comes for it's ability to join datasets together. Now, if these datasets both produce a UPRN with a different datatype when being loaded into Pandas then join won't work. Furthermore depending on how a UPRN value is applied where loading into Pandas it may very well alter it's value.
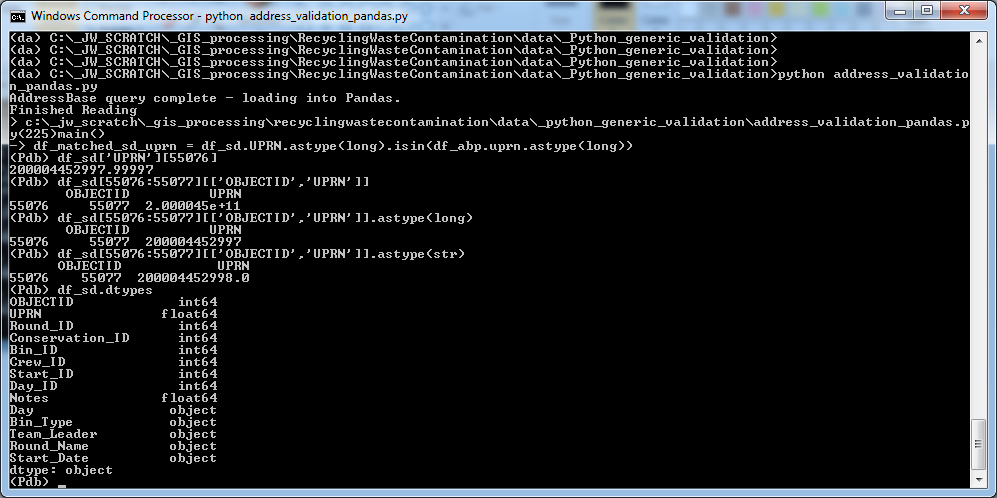
Initially it seemed that string values would be the right ones to use where adding to a Pandas data frame however some values were rendered using decimals and others were not. For example I might obtain both:
10012180110
or
10012180110.0
depending on the source CSV file used to create the Pandas data frame.
Setting the values to float64 works to an extent although I’ve been finding numbers get changed slightly. For example the UPRN value:
10012180110
was being loaded as:
10012180109.99994
Assigning UPRNs as floats also resulted in them being displayed via scientific notation. The same thing happens where UPRN values are loaded into Excel for some of them. This makes reading them in a debugging situation that much more difficult but essentially it appears the scientific representation of these numbers results in them being rendered as above.
Where attempting to run a join type function within Pandas this is a problem as Pandas can assign different data types to the UPRN values. In five different source .csv datasets including a UPRN value the data type was represented as an int; a long; a float; and a string.
The method I use to work around this is accept what Pandas assigns to the UPRN column for any source datasets and when processing it round each value and cast it as a long:
df_sd[['UPRN']] = df_sd[['UPRN']].round().astype(long)
This method works even when the initial data type is defined as a string.
I also ensure that where loading my gazetteer data that I assign the UPRN as a float64.
0 comments
Additional comments have been disabled for this entry
An entry posted on July 28, 2017.
Categories: Data , GIS , Open Source and Python